
Sunday, December 20, 2020
Saturday, December 19, 2020

Friday, December 18, 2020
Friendly-traceback of the day (Dec. 18/20)

Feel free to make suggestions as to what other Exception could benefit from a Friendly-traceback treatment.
Thursday, December 17, 2020
pytest apparently modifies calls to range
As I work making Friendly-traceback provide more useful information regarding the cause of an exception, I sometimes encounter weird "corner cases" about either Python itself [1] or occasionally about pytest [2]. Today, it was pytest's turn to give me a new puzzle to solve.
Consider the following:
range(1.0)
If you run this, Python will give you a TypeError: 'float' object cannot be interpreted as an integer
Using Friendly-traceback's console [3], I get something slightly more informative.

Actually, I can get even more information using "explain()":

Time to add this new working case to the unit test suite. I create a barebone one for the purpose of this blog, without capturing the output and comparing with what is expected.
import friendly_traceback
def test():
try:
range(1.0)
except:
friendly_traceback.explain_traceback()
if __name__ == '__main__':
test()
Here's what happens if I run this using Python:

In order to provide this kind of explanation, Friendly-traceback looks at the content of the frame where the exception was raised and does its best to deduce what needs to be changed. For example, if we modify the above example to use a variable called "end" instead of using a literal, here's what we get.

When writing unit tests, I make sure that such highlighted hints are reproduced exactly in the output that is captured. So, what happens if we run the previous example using pytest? ...

A new float variable, "start", has suddenly appeared, seemingly out of nowhere. Note that this pytest oddity is not revealed if we use a string instead of a float as the wrong type of argument.

Time to move on to handling other cases ...
[1] See this blogpost.
[2] An issue that I filed about a previous case seems to have disappeared and all that remains is this question on Stack Overflow.
[3] This is my local development version; the example shown here will be handled by versions 0.2.8 and later, to be released on pypi.
Wednesday, December 09, 2020
IPython and Friendly-traceback
This is a quick update on the status of Friendly-traceback. As of today, it works with the IPython console, and works even better in a JupyterLab environment.
First, a comparison with using it in the new Windows terminal making use of Rich for syntax highlighting, which is something that has been working for quite a while now.

Next, is the same example in an IPython console, running in a Windows terminal.

I've tried to use Rich to do syntax colouring with the IPython console ... but the result is really disappointing.

Finally, here's what it looks like in the JupyterLab environment.

Right now, it is not possible to select a different theme for syntax highlighting; this will have to wait until later.
To find out more about Friendly-traceback (excluding this new IPython experimental support), please consult the documentation.
Saturday, October 24, 2020
Friendly-traceback: work in progress
It's been almost two months since my last blog post and I feel guilty of not having taken the time to write more regularly. I should really tell you about how fantastic Will McGugan's Rich is, and how I have customized it for my projects. I should also tell you how Sylvain Desodt's DidYouMeanPython has been influencing Friendly-traceback latest developments. Also worthy of note is how Alex Hall's FutureCoder project is incorporating so many neat tools that it feels like a real honour that he has incorporated Friendly-traceback in it.
Alas, while I have been busy making many changes and addition to the code, the documentation is hopelessly behind and no longer gives a correct picture of what Friendly-traceback is now capable of.
So much to do, so little time. So, I will just end with a picture, and go back to coding, with a promise of writing more ... soon I hope.

Saturday, August 29, 2020

Saturday, August 22, 2020

Monday, August 10, 2020
Rich + Friendly-traceback: first look
After a couple of hours of work, I have been able to use Rich to add colour to Friendly-traceback. Rich is a fantastic project, which has already gotten a fair bit of attention and deserves even more.
The following is just a preview of things to come; it is just a quick proof of concept.


There is, of course, much, much more to come ...
Update: more work in progress

Tuesday, August 04, 2020
Identifying misleading type hints
Yesterday on Twitter:





For beginners, unintentional type hints can be really confusing. No SyntaxError, no traceback to guide the beginners ... Still, could Friendly-traceback help?

I've already mentioned how Friendly-traceback could be used by Thonny, and how it could also be used with Mu. What about IDLE?

Yes, it can. And what if it is typos and not type hints that are causing problems?

Note: This is freshly written code. The documentation really needs to be updated to reflect the most recent changes.
Wednesday, July 29, 2020
HackInScience: friendly Python learning
A short while ago I discovered HackInScience, a fantastic site for learning Python by doing exercises. It currently includes 68 programming exercises, with increasing level of difficulty.
I learned about it via an issue filed for Friendly-traceback: yes, HackInScience does use Friendly-traceback to provide feedback to users when their code raises Python exceptions. These real-life experiences have resulted in additional cases being covered by Friendly-traceback: there are now 128 different test cases, each providing more helpful explanation as to what went wrong than that offered by Python. Python versions 3.6 to 3.9 inclusively are supported.
Previously, I thought I would get feedback about missing cases from teachers or beginners using either Mu or Thonny - both of which can make use of Friendly-traceback. However, this has not been the case yet, and this makes me extremely grateful for the feedback received from HackInScience.
While Friendly-traceback can provide feedback in either English or French [1], HackInScience only uses the English version - this, in spite of the fact that it was created by four French programmers. I suspect that it is only a matter of time until they make a French version of their site.
One excellent additional feature provided by HackInScience is the addition of formatting (including some colour) in the output provided by Friendly-traceback.

The additional cases provided by Julien Palard from HackInScience have motivated me to clear out the accumulated backlog of test cases I had identified on my own. Now, there is only one (new) issue: enabling coloured output from Friendly-traceback's console.
Please, feel free to interrupt my work on this new issue by submitting new cases that are not covered by Friendly-traceback! ;-)
[1] Anyone interested in providing translations in other languages is definitely welcome!
I learned about it via an issue filed for Friendly-traceback: yes, HackInScience does use Friendly-traceback to provide feedback to users when their code raises Python exceptions. These real-life experiences have resulted in additional cases being covered by Friendly-traceback: there are now 128 different test cases, each providing more helpful explanation as to what went wrong than that offered by Python. Python versions 3.6 to 3.9 inclusively are supported.
Previously, I thought I would get feedback about missing cases from teachers or beginners using either Mu or Thonny - both of which can make use of Friendly-traceback. However, this has not been the case yet, and this makes me extremely grateful for the feedback received from HackInScience.
While Friendly-traceback can provide feedback in either English or French [1], HackInScience only uses the English version - this, in spite of the fact that it was created by four French programmers. I suspect that it is only a matter of time until they make a French version of their site.
One excellent additional feature provided by HackInScience is the addition of formatting (including some colour) in the output provided by Friendly-traceback.

The additional cases provided by Julien Palard from HackInScience have motivated me to clear out the accumulated backlog of test cases I had identified on my own. Now, there is only one (new) issue: enabling coloured output from Friendly-traceback's console.
Please, feel free to interrupt my work on this new issue by submitting new cases that are not covered by Friendly-traceback! ;-)
[1] Anyone interested in providing translations in other languages is definitely welcome!
Monday, March 02, 2020
True constants in Python - part 2, and a challenge
Like the title says, this is the second post on this topic. If you have not done so, you should really read the first one, which is much shorter, before continuing to read here.
The first clue is that, rather than executing test.py as the main module, I imported it. Can you think of a situation where this would make a difference?
I'll leave a bit of space below to give you the opportunity to possibly go back to part 1, without reading about the solution below.
Back in 2002, with the adoption of PEP 302, Python enabled programmers to modify what happens when a module is imported; this is known as an import hook. For example, it is possible to modify the source code in a module prior to it being executed by Python. This is NOT what I have done here - but I have done this for other examples that I will refer to below.
If the only thing required would be to modify the source, one could use what is described in PEP 263 and define a custom encoding that would transform the source. In this case, by adding an encoding declaration, it would have been possible to run test.py directly rather than executing it. I thought of it a while ago but, in order to cover all possible cases, one would pretty much have to write a complete parser for Python that could be used to identify and replace the various assignments statement done by print statements so as to show what you saw in part 1. However, this still would not be enough to protect against the reassignement done externally, like I did with
test.UPPERCASE = 1
The actual solution I used required three separate steps. The challenge I will mention at the end is to reduce this to two steps - something that I think is quite possible but that I have not been able to do yet - and to remove one left-over "cheat" which would allow one to redefine a constant by monkeypatching. I think that this is possible but I have not actually sat down to actually do it. I thought of waiting for a few days to give an added incentive for anyone who would like to try and get the bragging rights of having it done first! ;-)
When importing a module, Python roughly does the following:
The first clue
The first clue is that, rather than executing test.py as the main module, I imported it. Can you think of a situation where this would make a difference?
I'll leave a bit of space below to give you the opportunity to possibly go back to part 1, without reading about the solution below.
PEP 302
Back in 2002, with the adoption of PEP 302, Python enabled programmers to modify what happens when a module is imported; this is known as an import hook. For example, it is possible to modify the source code in a module prior to it being executed by Python. This is NOT what I have done here - but I have done this for other examples that I will refer to below.
If the only thing required would be to modify the source, one could use what is described in PEP 263 and define a custom encoding that would transform the source. In this case, by adding an encoding declaration, it would have been possible to run test.py directly rather than executing it. I thought of it a while ago but, in order to cover all possible cases, one would pretty much have to write a complete parser for Python that could be used to identify and replace the various assignments statement done by print statements so as to show what you saw in part 1. However, this still would not be enough to protect against the reassignement done externally, like I did with
test.UPPERCASE = 1
The actual solution I used required three separate steps. The challenge I will mention at the end is to reduce this to two steps - something that I think is quite possible but that I have not been able to do yet - and to remove one left-over "cheat" which would allow one to redefine a constant by monkeypatching. I think that this is possible but I have not actually sat down to actually do it. I thought of waiting for a few days to give an added incentive for anyone who would like to try and get the bragging rights of having it done first! ;-)
Step 1
Step 1 and 2 involve an import hook. They are independent one of another and can be done in any order.When importing a module, Python roughly does the following:
- Find the source code
- Create a module object
- Execute the source code in the module object's dict.
The module object created by Python comes with a dict that is, in some sense, "read-only": you cannot write code to modify its behaviour, nor replace it by a custom dict. (However, see the challenge.) However, one can define a custom dict, which is designed so that its various methods (__setitem__, __delitem__, etc.) prevent the reassignment of variables we intend to be constants. In the example I have chosen, these are variables whose names are in UPPERCASE. (Not shown in the example of part 1: I have also added a scan of the code to identify any variable that used the type hint Final and add them automatically to the list of variables intended to be constants.)
Instead of executing the code in the module object's dict, it is executed in this special dict. The content of that dict is then copied into the module object's dict.
Doing this ensures that code run directly in the module is guaranteed to prevent variable reassignement. At least, I have not found a way to cheat from within a module and change the value of variables intended to be a constant.
Step 2
Step 2 is to define a custom class that prevent changes of attributes. This custom class is used to replace the module's own class, something that can be done.
Step 3
Step 3 is to make Python use our import hook. To do so, we must have some code being executed earlier than what is shown. There are a couple of ways to do this as describe in the Site-specific configuration hook section of the Python documentation. The method I have chosen is one that is easily done on an ad-hoc basis. I created a file named usercustomize.py whose content is the following:
from ideas.examples import constants
constants.add_hook()
This calls my code that sets up an import hook as described above. To have Python execute this code, I set the environment variable PYTHONPATH to be equal to the directory where usercustomize is located. On Windows (which is what I use), this is most easily achieve by navigating to that directory in the terminal and entering the following:
set PYTHONPATH=%CD%
Doing so will ensure that the code in usercustomize.py is executed before any user code.
The challenge
As mentioned in part 1, attempting to modify the value of a constant from outside, as in:
This leaves one possible cheat. From an external module, instead of writing
import test
test.UPPERCASE = "new value"
which is prevented, one can use the following cheat
import test
test.__dict__["UPPERCASE"] = "new value"
This is because the module's __dict__ is a "normal" Python dict.
However, instead of using a module object created by Python, it should be possible to create a custom module object that uses something like the special dict mentioned before. Thus one would not need to change the way that Python execute code in the module's dict.
The challenge is to write code that creates such a module object. I would not be surprised if there remained some other ways to cheat after doing so, but hopefully none as obvious as the one shown above.
The code I have written is part of my project named ideas. The actual code for the constants example is given by this link. See also the documentation for the project. Note that, token_utils mentioned in the documentation has been put in a separate project; I need to update the documentation.
Both ideas and token-utils can be installed from Pypi.org as usual.
import test
test.__dict__["UPPERCASE"] = "new value"
This is because the module's __dict__ is a "normal" Python dict.
However, instead of using a module object created by Python, it should be possible to create a custom module object that uses something like the special dict mentioned before. Thus one would not need to change the way that Python execute code in the module's dict.
The challenge is to write code that creates such a module object. I would not be surprised if there remained some other ways to cheat after doing so, but hopefully none as obvious as the one shown above.
Resources
The code I have written is part of my project named ideas. The actual code for the constants example is given by this link. See also the documentation for the project. Note that, token_utils mentioned in the documentation has been put in a separate project; I need to update the documentation.
Both ideas and token-utils can be installed from Pypi.org as usual.
True constants in Python - part 1
tl;dr: I'm always trying to see if what everyone "knows to be true" is really true...
In many programming languages, you can define constants via some special declaration. For example, in Java you can apparently write something like:
and this will result in a value that cannot be changed. I wrote "apparently" since I do not program in Java and rely on what other people write.
Everyone "knows" that you cannot do the same in Python. If you want to define constants, according to Python's PEP 8, what you should do is the following
Thus, if I write in a module
TOTAL = 1
# some code
TOTAL = 2
the value of the variable will have changed.
If you are willing to use optional type declaration and either use Python 3.8 with the typing module, or some earlier version of Python but using also the third-party typing-extension package, you can use something like the following:
and use a tool like mypy that will check to see if the value of is changed anywhere, reporting if it does so. However, if you do run such an incorrect program (according to mypy), it will still execute properly, and the value of the "constant" will indeed change.
For people that want something a bit more robust, it is often recommended to use some special object (that could live in a separate module) whose attributes cannot change once assigned. However, this does not prevent one from deleting the value of the "constant object" (either by mistake within the module, or by monkeypatching) and reassign it.
Every Python programmer knows that the situation as described above is the final word on the possibility of creating constants in Python ... or is it?
For example, here's a screen capture of an actual module (called test.py)
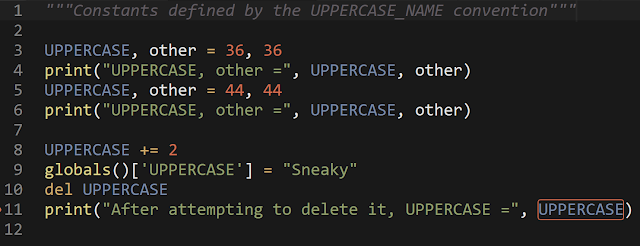
Notice how the linter in my editor has flagged an apparent error (using UPPERCASE after deleting it.) And here's the result of importing this module, and then attempting to change the value of the constant.

Can you think of how I might have done this? (No photoshop, only the normal Python interpreter used.)
In part 2 , I explain how I have done this and will leave you with a (small) challenge.
In many programming languages, you can define constants via some special declaration. For example, in Java you can apparently write something like:
public static final String CONST_NAME = "Name";and this will result in a value that cannot be changed. I wrote "apparently" since I do not program in Java and rely on what other people write.
Everyone "knows" that you cannot do the same in Python. If you want to define constants, according to Python's PEP 8, what you should do is the following
Constants are usually defined on a module level and written in all capital letters with underscores separating words. Examples include MAX_OVERFLOW and TOTAL.and rely on the fact that everyone will respect this convention. However, nothing prevents you from redefining the value of these variables later in the same module, or from outside (monkeypatching) when importing the module.
Thus, if I write in a module
TOTAL = 1
# some code
TOTAL = 2
the value of the variable will have changed.
If you are willing to use optional type declaration and either use Python 3.8 with the typing module, or some earlier version of Python but using also the third-party typing-extension package, you can use something like the following:
from typing import Final
and use a tool like mypy that will check to see if the value of is changed anywhere, reporting if it does so. However, if you do run such an incorrect program (according to mypy), it will still execute properly, and the value of the "constant" will indeed change.
For people that want something a bit more robust, it is often recommended to use some special object (that could live in a separate module) whose attributes cannot change once assigned. However, this does not prevent one from deleting the value of the "constant object" (either by mistake within the module, or by monkeypatching) and reassign it.
Every Python programmer knows that the situation as described above is the final word on the possibility of creating constants in Python ... or is it?
For example, here's a screen capture of an actual module (called test.py)

Notice how the linter in my editor has flagged an apparent error (using UPPERCASE after deleting it.) And here's the result of importing this module, and then attempting to change the value of the constant.

Can you think of how I might have done this? (No photoshop, only the normal Python interpreter used.)
In part 2 , I explain how I have done this and will leave you with a (small) challenge.
Friday, February 28, 2020
Implicit multiplication in Python - part 1
Quoting from a post from Guido van Rossum
and what mathematicians would write by transforming something that is currently a SyntaxError into valid Python code?
>>> from ideas.examples import implicit_multiplication as mul
>>> hook = mul.add_hook()
>>> from ideas import console
>>> console.start()
Configuration values for the console:
callback_params: {'show_original': False,
'show_transformed': False}
transform_source from ideas.examples.implicit_multiplication
--------------------------------------------------
Ideas Console version 0.0.7a. [Python version: 3.7.3]
~>> 2(3 + 4)
14
~>> a = 3
~>> b = 4
~>> 2a
6
~>> a b
12
All that is needed is to change the way the code is tokenized before the code is parsed by Python.
... The power of visual processing really becomes apparent when you combineWhat if we could do something half-way between what Python currently allow
multiple operators. For example, consider the distributive law
mul(n, add(x, y)) == add(mul(n, x), mul(n, y)) (5)
That was painful to write, and I believe that at first you won't see the
pattern (or at least you wouldn't have immediately seen it if I hadn't
mentioned this was the distributive law).
Compare to
n * (x + y) == n * x + n * y (5a)
Notice how this also uses relative operator priorities. Often
mathematicians write this even more compact
n(x+y) == nx + ny (5b)
but alas, that currently goes beyond the capacities of Python's parser.
...
Now, programming isn't exactly the same activity as math, but we all know
that Readability Counts, and this is where operator overloading in Python
comes in. ...
and what mathematicians would write by transforming something that is currently a SyntaxError into valid Python code?
>>> from ideas.examples import implicit_multiplication as mul
>>> hook = mul.add_hook()
>>> from ideas import console
>>> console.start()
Configuration values for the console:
callback_params: {'show_original': False,
'show_transformed': False}
transform_source from ideas.examples.implicit_multiplication
--------------------------------------------------
Ideas Console version 0.0.7a. [Python version: 3.7.3]
~>> 2(3 + 4)
14
~>> a = 3
~>> b = 4
~>> 2a
6
~>> a b
12
All that is needed is to change the way the code is tokenized before the code is parsed by Python.
Monday, February 24, 2020
From a rejected Pycon talk to a new project.
Like many others, my talk proposal (early draft here) for Pycon US was rejected. So, I decided to spend some time putting everything in a new project instead. (Documentation here.) It is still a rough draft, but usable ... and since I've mentioned it in a few other places, I thought I should mention it here as well.

Subscribe to:
Posts (Atom)