Python 3.11 is barely out and already the 3.12 alpha has some improvements for NameError messages. I suspect that these will be backported to 3.11 in time for the next release.
On Ideas Python Discussion, Pamela Fox suggested that it might be useful to consider potential missing import when a NameError was raised. Thus, instead of having
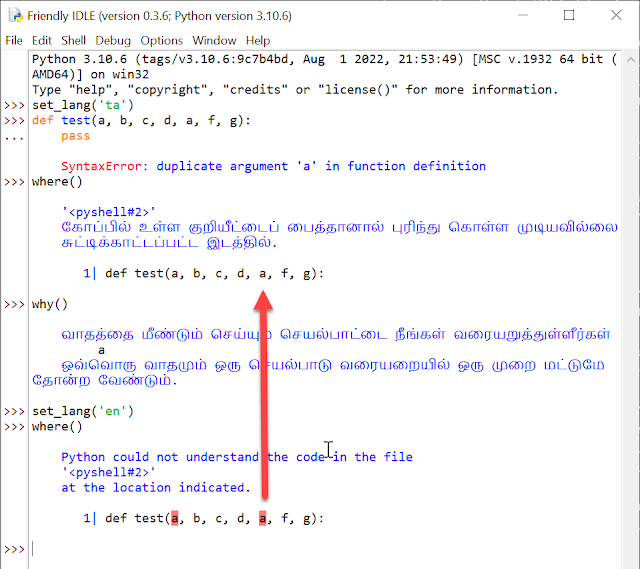
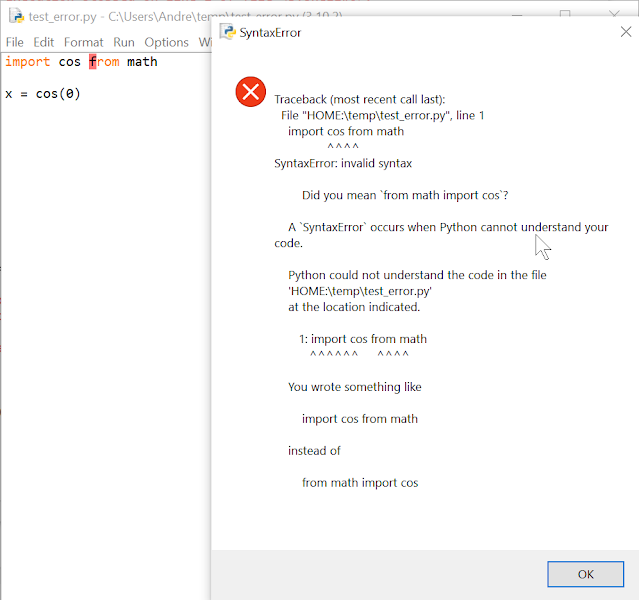
>>> stream = io.StringIO() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'io' is not defined. Did you mean 'id'?
one would see
>>> stream = io.StringIO() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'io' is not defined. Did you mean 'id'? Or did you forget to import 'io'?
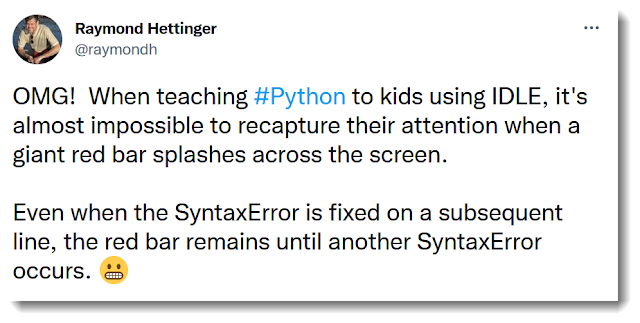
Of course, something like this was already done by friendly/friendly-traceback (aka Friendly). However, in this particular case, the information provided by Friendly contained too much information; this has been since fixed.
To no one's surprise, Pablo Galindo Salgado came up with a version of this for Python, where names found in sys.stdlib_module_names were considered and potentially added, with the result as initially suggested by Pamela Fox. Pamela then made a second suggestion to see if names of popular third-party libraries could also be considered. This, for now, appears to be out of scope for Python.
This set the stage for a friendly (pun intended) competition...
I decided to revise what I had done for Friendly in such cases and found some room for improvements. First, let's look at a couple of examples (with screenshots) of the new behaviour for Python.

As we can see with the first example, Python first makes suggestions about potential typos ('io' instead of 'id') followed by the suggestion about a missing import. Note that 'id' is a builtin who is never used with a dotted attribute.
The second example suggest a missing import only. However, as I am using Windows, this module does not exist.
Can Friendly do better? Note that Friendly can be used with Python 3.6+ (including Python 3.12), all of which would show the same output. I've chosen to use Python 3.10 for this example, as I will explain near the end of this post.

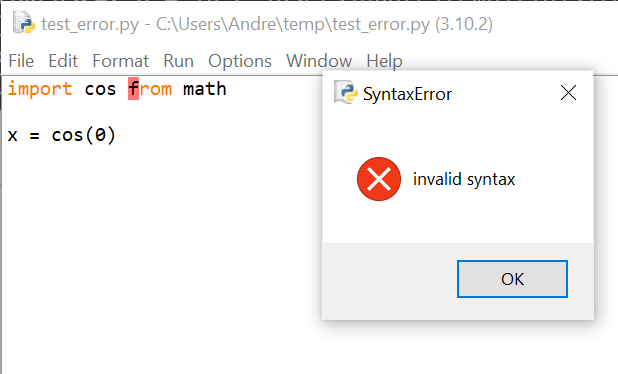
The message included in the Python traceback does not include the additional hint about a missing import in this case. However, Friendly adds it on its own. Note that it does not suggest 'id' as a potential typo. But what if we had made such a typo?

Here, Friendly does make the suggestion about a potential typo. What about the second example given above?

Friendly also uses sys.stdlib_module_names initially, but also check with importlib.util.find_spec() to see if the module can be located.
It can also find potentially relevant third-party modules that are installed, but not yet imported.

Using importlib.util.find_spec() allows us to implement Pamela Fox's suggestion about suggesting third-party modules that are installed.
However, we can do even better with some dedicated code. To demonstrate this, I need to use the latest addition to the "friendly-traceback family" - which I have only tested with Python 3.10 so far.

I'll likely have more to say about friendly_pandas in the near future.
Final thoughts
For those excited about the improved traceback with Python 3.11 and PEP 657: Fine-grained error locations in tracebacks, but cannot yet install Python 3.11, please note that Friendly can already something similar, if not better with any Python version 3.6.1+

I say "better" because, unlike Python's traceback, the information is not limited to a single line of code: