All too often, on various forums I see someone asking something like "Convince me to learn X". I'm immediately tempted to simply answer "Don't learn it" .... and be prepared to be downvoted into oblivion.
Almost invariably, learning X will take some time ... a lot of time if you are to learn it well.
If you are not willing to spend a much, much smaller amount of time finding out on your own if X is worth learning, then you definitely won't find the time to learn it.
If you do not have the time to figure out from what's already available about whether or not it's worth learning X, why should I expect that you will give any weight to my opinion? Why should I spend my time writing down reasons as to why you should learn it?
If your question is a vague "Should I learn X or Y?", then it will only give rise to some quasi-religious wars between fans of X and fans of Y, reflecting only the readership of that forum.
If you want to know if it would be better to learn X or Y to accomplish a specific task, then it is a different question, which may very well deserve an answer based on the specificity of the task.
However, if you want to know if you should learn X ... do everyone a favour and simply start learning it: you will soon be able to decide on your own if you should pursue or not. And if you do not like this answer, then "Don't learn X".
Thursday, December 31, 2015
Wednesday, December 30, 2015
i18n: an unusual scenario
Reeborg's World currently has a "default" English version, a French version, and a partially implemented Korean version. Even if one forgets about the fairly extensive documentation [en, fr, ko], creating a new language version can be a rather daunting task.
For most applications, creating a new language version requires to create a collection of strings as a template for translation and provide a translation for each string in that template. The standard approach for doing this is to use gettext [0]. Would-be translators then have to either install some software (poedit is the standard) or register as a translator on some web-based site (e.g. https://translatewiki.net/) where they may have to prove their worth before being approved as a translator. These extra steps (installing some software or jumping through some hoops to register on some site) can be a turn off. [1]
One of my motivations for dropping RUR-PLE in favour of a web-based version was to reduce the friction for the end user. Initially, installing RUR-PLE meant 1) installing Python; 2) installing the corresponding version of wxPython; 3) downloading RUR-PLE itself as a zip file. Eventually, some volunteers helped to create various installers for it ... but this was not something I could easily do myself and it still required end-users (say: teachers in a classroom) to install some "unusual" software which, I found out, was not (easily) possible to do in some school environment.
By contrast, using Reeborg's World simply requires to open the site in a browser [2]. By choice, no login is required as I want the end-user experience to be as painless as possible; everything is run client-side. I would like to create an "as painless as possible" experience as well for would-be translators.
To understand what is required for a full translation (excluding the documentation!) of the user interface, I will use a simple example. Imagine that we want the end-user to be able to run the following program (using Python):
move()
take("token")
This being a tool to teach Python, we have also to enable the end-user to type
help(take)
and get some appropriate help. Here's the result of doing so:

Since Reeborg's World also support Javascript, we could run
move();
take("token");
Finally, since it supports Blockly as well, the same program could be executed via:

where is the representation of a "token" in Reeborg's World, one of a dozen basic objects that can be interacted with by Reeborg. Here's how the same program would appear to a French user using Blockly
is the representation of a "token" in Reeborg's World, one of a dozen basic objects that can be interacted with by Reeborg. Here's how the same program would appear to a French user using Blockly

from which you can easily deduce how to write the corresponding program using either Python or Javascript.
Having this basic scenario in mind, here's what's needed to translate:
1. The main html page (currently world.html for the English version and monde.html for the French version - but this will likely change in the near future). This can be done using a template and creating static pages by inserting the appropriate translation strings into the template. (This is not how it is done currently ... but should soon be.)
2. Create a complete Python module for the target language (currently reeborg_en.py for the English version) containing the appropriate function definitions something like
def take(obj=None):
"""Takes an object. If more than one type of objects is at
Reeborg's location, the type must be specified as an
argument, otherwise an exception will be raised.
"""
if obj is None:
_take_()
else:
_take_(obj)
3. Create a complete Javascript module (currently reeborg_en.js) for a similar definition
var take, ...;
reset_definitions = function () {
...
take = _take_;
}
4. Create the appropriate translation strings so that Blockly programs can be translated into the target language (or, in some cases, ensure that a consistent English-version is used), something like
translation["take"] = "prend";
translation["token"] = "jeton";
translation_to_english["jeton"] = "token";
Like Blockly, I do not plan to make special allowance for plural forms of words. While 1 and most of 4 above can be done using the standard gettext approach, 2 and 3 require a different approach. I have asked for suggestions about this on HackerNews ... and, unsurprisingly, my query received no visible attention.[3] So, I have come up with a plan to implement a custom and "unified" solution, applicable to all four steps above and somewhat inspired by the gettext approach. I want all of this to be done (client-side) via a custom page on my site, similar to the idea of translatewiki, but without requiring any login. The translators would have to save a file (end result) to their computer and email it to me ... which, hopefully, would not be seen as being too onerous for someone wanting support in their own language. (I expect that most translations will be provided by educators wanting to use Reeborg's World.) Of course, alternatively, they could clone the repo, make the required changes, and submit a pull request ... but that's not exactly painless!
If you have read this far, it likely means that you've had some experience with i18n strategies ... and perhaps have suggestions to offer which may help me avoid reinventing the wheel! ;-)
[0] Indeed this is what I (mostly) ended up using with RUR-PLE, whose interface is available in 7 languages).
[1] For the record, I wanted to correct a translation for Blockly where "to" was correctly translated into French as "à" except in one context where it should have been translated as "pour" ... but, upon loggin in, I was presented with a completely unrelated other translation task, with some hint that additional tasks were to come before I could be approved... and with no guarantee that the correction I wanted to make would be accepted. In the end, I just gave up and implemented the correction in the version I use on Reeborg's World. I don't think that my reluctance at jumping through the hoops mentioned is particularly unusual ... especially to those that have done editing on Wikipedia :-/
[2] I am aware that some schools have filters that prevent browsing on some non-approved site. From what I understand, it is easier to get permission to add new allowed sites than it is to install some "unusual" software. Furthermore, unlike RUR-PLE, Reeborg's World can be used from someone else's computer (e.g. from a Public Library) where it would definitely be impossible to install some software.
[3] I didn't bother with StackOverflow as this was the type of question often flagged as not being too vague or something similar.
For most applications, creating a new language version requires to create a collection of strings as a template for translation and provide a translation for each string in that template. The standard approach for doing this is to use gettext [0]. Would-be translators then have to either install some software (poedit is the standard) or register as a translator on some web-based site (e.g. https://translatewiki.net/) where they may have to prove their worth before being approved as a translator. These extra steps (installing some software or jumping through some hoops to register on some site) can be a turn off. [1]
One of my motivations for dropping RUR-PLE in favour of a web-based version was to reduce the friction for the end user. Initially, installing RUR-PLE meant 1) installing Python; 2) installing the corresponding version of wxPython; 3) downloading RUR-PLE itself as a zip file. Eventually, some volunteers helped to create various installers for it ... but this was not something I could easily do myself and it still required end-users (say: teachers in a classroom) to install some "unusual" software which, I found out, was not (easily) possible to do in some school environment.
By contrast, using Reeborg's World simply requires to open the site in a browser [2]. By choice, no login is required as I want the end-user experience to be as painless as possible; everything is run client-side. I would like to create an "as painless as possible" experience as well for would-be translators.
To understand what is required for a full translation (excluding the documentation!) of the user interface, I will use a simple example. Imagine that we want the end-user to be able to run the following program (using Python):
move()
take("token")
This being a tool to teach Python, we have also to enable the end-user to type
help(take)
and get some appropriate help. Here's the result of doing so:

Since Reeborg's World also support Javascript, we could run
move();
take("token");
Finally, since it supports Blockly as well, the same program could be executed via:

where
is the representation of a "token" in Reeborg's World, one of a dozen basic objects that can be interacted with by Reeborg. Here's how the same program would appear to a French user using Blockly
from which you can easily deduce how to write the corresponding program using either Python or Javascript.
Having this basic scenario in mind, here's what's needed to translate:
1. The main html page (currently world.html for the English version and monde.html for the French version - but this will likely change in the near future). This can be done using a template and creating static pages by inserting the appropriate translation strings into the template. (This is not how it is done currently ... but should soon be.)
2. Create a complete Python module for the target language (currently reeborg_en.py for the English version) containing the appropriate function definitions something like
def take(obj=None):
"""Takes an object. If more than one type of objects is at
Reeborg's location, the type must be specified as an
argument, otherwise an exception will be raised.
"""
if obj is None:
_take_()
else:
_take_(obj)
3. Create a complete Javascript module (currently reeborg_en.js) for a similar definition
var take, ...;
reset_definitions = function () {
...
take = _take_;
}
4. Create the appropriate translation strings so that Blockly programs can be translated into the target language (or, in some cases, ensure that a consistent English-version is used), something like
translation["take"] = "prend";
translation["token"] = "jeton";
translation_to_english["jeton"] = "token";
Like Blockly, I do not plan to make special allowance for plural forms of words. While 1 and most of 4 above can be done using the standard gettext approach, 2 and 3 require a different approach. I have asked for suggestions about this on HackerNews ... and, unsurprisingly, my query received no visible attention.[3] So, I have come up with a plan to implement a custom and "unified" solution, applicable to all four steps above and somewhat inspired by the gettext approach. I want all of this to be done (client-side) via a custom page on my site, similar to the idea of translatewiki, but without requiring any login. The translators would have to save a file (end result) to their computer and email it to me ... which, hopefully, would not be seen as being too onerous for someone wanting support in their own language. (I expect that most translations will be provided by educators wanting to use Reeborg's World.) Of course, alternatively, they could clone the repo, make the required changes, and submit a pull request ... but that's not exactly painless!
If you have read this far, it likely means that you've had some experience with i18n strategies ... and perhaps have suggestions to offer which may help me avoid reinventing the wheel! ;-)
[0] Indeed this is what I (mostly) ended up using with RUR-PLE, whose interface is available in 7 languages).
[1] For the record, I wanted to correct a translation for Blockly where "to" was correctly translated into French as "à" except in one context where it should have been translated as "pour" ... but, upon loggin in, I was presented with a completely unrelated other translation task, with some hint that additional tasks were to come before I could be approved... and with no guarantee that the correction I wanted to make would be accepted. In the end, I just gave up and implemented the correction in the version I use on Reeborg's World. I don't think that my reluctance at jumping through the hoops mentioned is particularly unusual ... especially to those that have done editing on Wikipedia :-/
[2] I am aware that some schools have filters that prevent browsing on some non-approved site. From what I understand, it is easier to get permission to add new allowed sites than it is to install some "unusual" software. Furthermore, unlike RUR-PLE, Reeborg's World can be used from someone else's computer (e.g. from a Public Library) where it would definitely be impossible to install some software.
[3] I didn't bother with StackOverflow as this was the type of question often flagged as not being too vague or something similar.
Wednesday, December 23, 2015
Planning to drop CoffeeScript support for Reeborg's World
When I started working on Reeborg's World, I thought it would eventually be a good site to learn the basics of various programming languages, with fun puzzles to solve. However, I found that it myself including more material for Python (and Javascript) including the recent Blockly addition, with no new programming language easily added. I also have been reading various posts about people suggesting that CoffeeScript was good to use/learn only after having had a good grasp of Javascript. By then, programmers would find the tasks on Reeborg's World rather trivial to solve and, in the absence of a good dedicated tutorial to CoffeeScript (or other languages), the appeal of using Reeborg's World to learn CoffeeScript would be rather minimal.
So, CoffeeScript support will be dropped, thus reducing slightly the code requiring to be maintained.
Of course, anyone finding it of value could just clone the repo and recover the CoffeeScript support.
So, CoffeeScript support will be dropped, thus reducing slightly the code requiring to be maintained.
Of course, anyone finding it of value could just clone the repo and recover the CoffeeScript support.
Blockly + Reeborg = fun
I've retrofitted Reeborg's World to include Blockly. You can select Blockly from the top. If you do so, I suggest you keep the editor open to see the generated code prior to its execution.
Note that this is a first implementation done in just a couple of days of programming. Bugs are likely present...
Note that this is a first implementation done in just a couple of days of programming. Bugs are likely present...
Tuesday, December 08, 2015
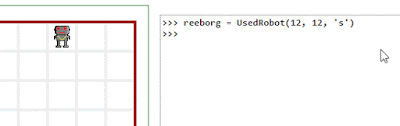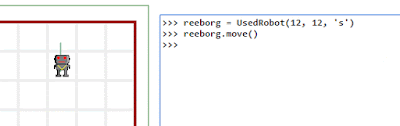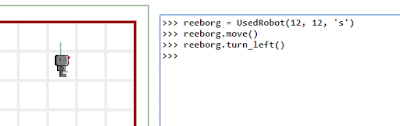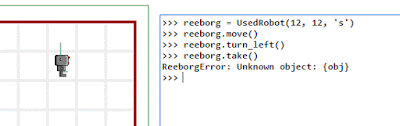
Reeborg: two major steps forward, a huge step back with Firefox
UPDATE: The Firefox problem was caused by using a function argument named "watch" ... which seemed like a good name... However, it appears to conflict with https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/watch
=======
I'm really happy with two new cool features for Reeborg's World ... but this happiness is nearly crushed by the fact that Reeborg's World is completely broken by Firefox 42.0. It still works with Google Chrome and even works with Microsoft Edge (gasp!) ... but not with Firefox. I tried to load a year old version of the site that did work with older version of Firefox: no go.
The two new features: it is possible to enable a "variable watch".

Of course, the speed of the animation can be controlled and even paused.
It is also possible to control Reeborg (or, write any Python code, really) using an REPL.
=======
I'm really happy with two new cool features for Reeborg's World ... but this happiness is nearly crushed by the fact that Reeborg's World is completely broken by Firefox 42.0. It still works with Google Chrome and even works with Microsoft Edge (gasp!) ... but not with Firefox. I tried to load a year old version of the site that did work with older version of Firefox: no go.
The two new features: it is possible to enable a "variable watch".

Of course, the speed of the animation can be controlled and even paused.
It is also possible to control Reeborg (or, write any Python code, really) using an REPL.

Wednesday, December 02, 2015
Revisiting an old friend, yet again
The most popular blog post I ever wrote was on a suggested alternative for type hinting in Python. This was likely due to the fact that the blog post was linked in PEP 484 which codified a syntax for type hinting.
The alternative syntax I had been suggesting was to use a clause introduced by a new keyword: where. (I had first discussed this idea more than 10 years ago.)
For example, instead of the approved type hinting syntax
I was suggesting to use something like the following:
Similarly, instead of using a comment to introduce type hinting for single variables
one would have used the following:
However, this alternative was never considered as a serious contender for type hinting since it was not compatible with Python 2.7, unlike the accepted syntax from PEP 484.
Still, as an experiment, I decided to see if I could use the approach mentioned in my last few blog posts and use an nonstandard where clause. And, of course, it is possible to do so, and it is surprisingly easy. :-)
The main details are to be found in three previous blog posts. However, to summarize, suppose you with to use a where clause like the one described above which would not have an effect on the actual execution of the Python program (same as for the current type hinting described in PEP 484). All you need to do is
1. include the line
2a) if the program to be run is the main program, instead of running it via
2b) If instead of having it run as the main program, you would like to import it, then you would include an extra import statement:
and run this program in the usual way. By importing "import_nonstandard" first, a new import hook is created which pre-processes any modules to be imported afterwards - in this case, to remove the where clause or, as I have described in previous posts, to define new keywords or even an entirely different syntax (French Python).
Note: None of the recent experiments are to be taken as serious proposals to modify Python.
Instead, they are a demonstration of what can be done (often in a surprisingly easy way)
with Python as it exists today.
The alternative syntax I had been suggesting was to use a clause introduced by a new keyword: where. (I had first discussed this idea more than 10 years ago.)
For example, instead of the approved type hinting syntax
def twice(i: int, next: Function[[int], int]) -> int:
return next(next(i))
I was suggesting to use something like the following:
def twice(i, next):
where:
i: int
next: Function[[int], int]
returns: int
return next(next(i))
Similarly, instead of using a comment to introduce type hinting for single variables
x = 3 # type: int
one would have used the following:
x = 3
where:
x: int
However, this alternative was never considered as a serious contender for type hinting since it was not compatible with Python 2.7, unlike the accepted syntax from PEP 484.
Still, as an experiment, I decided to see if I could use the approach mentioned in my last few blog posts and use an nonstandard where clause. And, of course, it is possible to do so, and it is surprisingly easy. :-)
The main details are to be found in three previous blog posts. However, to summarize, suppose you with to use a where clause like the one described above which would not have an effect on the actual execution of the Python program (same as for the current type hinting described in PEP 484). All you need to do is
1. include the line
from __nonstandard__ import where_clause
in your program.
2a) if the program to be run is the main program, instead of running it via
python my_program.py
you would do
python import_nonstandard.py my_program
instead, where import_nonstandard.py is in the directory "version 5" of this repository, and the relevant where_clause.py is in "version 6".
2b) If instead of having it run as the main program, you would like to import it, then you would include an extra import statement:
import import_nonstandard import my_program # rest of the code
and run this program in the usual way. By importing "import_nonstandard" first, a new import hook is created which pre-processes any modules to be imported afterwards - in this case, to remove the where clause or, as I have described in previous posts, to define new keywords or even an entirely different syntax (French Python).
Note: None of the recent experiments are to be taken as serious proposals to modify Python.
Instead, they are a demonstration of what can be done (often in a surprisingly easy way)
with Python as it exists today.
Tuesday, December 01, 2015
French Python ?
In two previous post, I showed how it was possible to transform some source code prior to having it executed. My original motivation was to see how one could add a new keyword ("repeat") to use as "repeat n:" and it be equivalent to "for _ in range(n):".
As part of the additional motivation for my experiment, I mentioned the following:
In one of his posts to python-ideas, Terry Jan Reddy mentioned a discussion on the idle-dev list about making idle friendlier to beginners. In one of his post, he mentioned the idea of having non-English keywords. This idea is not new. There already exists an unmaintained version with Chinese Keywords as well as a Lithuanian and Russion version. Maintaining a version based on a different language for keywords is surely not something simple ... nor I think it would be desirable. However, it might be possible to essentially achieve the same goal by using an approach I describe in the next section.
Even just adding new keywords can be quite difficult. For example, in this post, Eli Bendersky explains how one can add a new keyword to Python. "All" you ned to do is
As part of the additional motivation for my experiment, I mentioned the following:
In one of his posts to python-ideas, Terry Jan Reddy mentioned a discussion on the idle-dev list about making idle friendlier to beginners. In one of his post, he mentioned the idea of having non-English keywords. This idea is not new. There already exists an unmaintained version with Chinese Keywords as well as a Lithuanian and Russion version. Maintaining a version based on a different language for keywords is surely not something simple ... nor I think it would be desirable. However, it might be possible to essentially achieve the same goal by using an approach I describe in the next section.
Even just adding new keywords can be quite difficult. For example, in this post, Eli Bendersky explains how one can add a new keyword to Python. "All" you ned to do is
- Modify the grammar to add the new keyword
- Modify the AST generation code; this requires a knowledge of C
- Compile the AST into bytecode
- Recompile the modified Python interpreter
Not exactly for the faint of heart...
I thought I should revisit the idea I had to see how difficult it might be to create a French Python syntax. As it turned out, it was even simpler than implementing a new keyword. In addition to the code mentioned previously, the new function needed is simply:
def transform_source_code(text):
dictionary = {...}
toks = tokenize.generate_tokens(StringIO(text).readline)
result = []
result = []
for toktype, tokvalue, _, _, _ in toks:
if toktype == tokenize.NAME and tokvalue in dictionary:
result.append((toktype, dictionary[tokvalue]))
else:
result.append((toktype, tokvalue))
return tokenize.untokenize(result)
where the dictionary contains the equivalent (e.g. "Vrai": "True", etc.)
The one change I made from the previous version was to replace __experimental__ by __nonstandard__.
For example, here's a test program:
from __nonstandard__ import french_syntax
de math importe pi
imprime(pi)
imprime("The first 5 odd integers are:")
pour i dans intervalle(1, 11, 2):
imprime(i)
imprime("This should be false:", Vrai et Faux)
si pi == 3:
imprime("We must be in Indiana")
ousi pi > 4:
print("Non standard Euclidean space")
autrement:
print("There should be nothing about Indiana nor Euclidean space.")
de math importe pi
imprime(pi)
imprime("The first 5 odd integers are:")
pour i dans intervalle(1, 11, 2):
imprime(i)
imprime("This should be false:", Vrai et Faux)
si pi == 3:
imprime("We must be in Indiana")
ousi pi > 4:
print("Non standard Euclidean space")
autrement:
print("There should be nothing about Indiana nor Euclidean space.")
The code found in version 5 of this repository. Using this approach, it would be trivial to create localized Python versions suitable to introduce absolute beginners to programming concepts. I would not do this myself, here in Canada, but I could see the appeal in some other countries especially those where the English alphabet is not very well known by young learners.
Now, if only I could figure out how to use importlib instead of imp ...
Now, if only I could figure out how to use importlib instead of imp ...
Thursday, October 22, 2015
Cryptic Reeborg
Like many people, one of the main reasons I like Python so much is that Python programs are usually very readable ... at least for people that can read and understand English. This post is definitely not about making Python programs readable in the usual sense.
I like to think of Reeborg's World as a learning environment not only for beginners, but also as a fun and visual place to experiment with various Python features. For example, is it possible to give a different and interesting introduction to Python's "magic" methods within Reeborg's World? By this, I mean to replace the usual English names for methods by symbols. Here's one such quick attempt that may find its way into my Python tutorial.
Reeborg likes to collect objects. He can add (+) an object found in his world to his collection, or leave an object behind, by removing an object from his collection (-).
Reeborg's favourite objects are (smilie face) tokens: These can be represented in a program by ":-)" [I would have like to be able to use the unicode character ☺but it is not a valid Python identifier.]
These can be represented in a program by ":-)" [I would have like to be able to use the unicode character ☺but it is not a valid Python identifier.]
Reeborg can move forward (>) a set number of steps (> n); he can turn perpendicular to his direction of motion (^) either to his left (^ left) or to his right (^ right). Reeborg can also "invert" his position and turn around (~reeborg).
Reeborg can detect if there is a wall (|) immediately in front of him (| front) or to his right (| right); he can also build a wall if needed (| build).
Reeborg can detect if he has reached a goal (>> goal) or if he has reached a point where there is a wall in front of him (>> wall) or where there is an object [for instance, a token: >> ":-)"]. Here I would have preferred to use the __matmul__ symbol @ [as in @ goal], but it is not (yet) supported by Brython. When @ becomes supported, I may use >> as a "fast forward" indicator to vary the speed of the display update [thus >> 100 could be equivalent to think(100)].
Here's a quick implementation of the above, followed by two animated gifs illustrating the result in action.

[Note that turn_right() and turn_around() shown as comments on the image below must be defined by the student since Reeborg only knows turn_left().]

I like to think of Reeborg's World as a learning environment not only for beginners, but also as a fun and visual place to experiment with various Python features. For example, is it possible to give a different and interesting introduction to Python's "magic" methods within Reeborg's World? By this, I mean to replace the usual English names for methods by symbols. Here's one such quick attempt that may find its way into my Python tutorial.
Reeborg likes to collect objects. He can add (+) an object found in his world to his collection, or leave an object behind, by removing an object from his collection (-).
Reeborg's favourite objects are (smilie face) tokens:
These can be represented in a program by ":-)" [I would have like to be able to use the unicode character ☺but it is not a valid Python identifier.]Reeborg can move forward (>) a set number of steps (> n); he can turn perpendicular to his direction of motion (^) either to his left (^ left) or to his right (^ right). Reeborg can also "invert" his position and turn around (~reeborg).
Reeborg can detect if there is a wall (|) immediately in front of him (| front) or to his right (| right); he can also build a wall if needed (| build).
Reeborg can detect if he has reached a goal (>> goal) or if he has reached a point where there is a wall in front of him (>> wall) or where there is an object [for instance, a token: >> ":-)"]. Here I would have preferred to use the __matmul__ symbol @ [as in @ goal], but it is not (yet) supported by Brython. When @ becomes supported, I may use >> as a "fast forward" indicator to vary the speed of the display update [thus >> 100 could be equivalent to think(100)].
Here's a quick implementation of the above, followed by two animated gifs illustrating the result in action.
RUR.world.__remove_default_robot()
build = "build"
front = "front"
right = "right"
left = "left"
token = ":-)"
wall = "wall"
goal = "goal"
class Cryptic(UsedRobot):
def __add__(self, obj):
if obj == token:
self.take("token")
else:
self.take(obj)
def __sub__(self, obj):
if obj == token:
self.put("token")
else:
self.put(obj)
def __gt__(self, n):
for _ in range(n):
self.move()
def __or__(self, wall):
if wall == front:
return self.wall_in_front()
elif wall == right:
return self.wall_on_right()
elif wall == build:
self.build_wall()
else:
raise ReeborgError("Unknown wall action")
def __rshift__(self, obj):
while self.front_is_clear():
self.move()
def __xor__(self, direction):
if direction == left:
self.turn_left()
elif direction == right:
for _ in range(3):
self.turn_left()
def __rshift__(self, obj):
if obj == token:
return self.object_here()
if obj == goal:
return self.at_goal()
def __invert__(self):
self.turn_left()
self.turn_left()
reeborg = Cryptic(1, 1)
[Note that turn_right() and turn_around() shown as comments on the image below must be defined by the student since Reeborg only knows turn_left().]
Wednesday, October 14, 2015
from __experimental__ import something_new : running scripts from the command line.
EDIT: I just found out that the notation "from __experimental__ import" had already been suggested in a different context than the one I have been working on. Perhaps I should use "__nonstandard__" instead of "__experimental__" to avoid any confusion.
In a post I wrote yesterday, I mentioned a way to run "experimental" code containing non-standard Python syntax (e.g. new keywords, not recognized by Python's interpreter) by using an "import hook" to convert the code into a proper Python syntax prior to executing it. One caveat of the approach I used was that it only worked if the "experimental" code was imported. This restriction is also present in the MacroPy project (which is something I stumbled upon and is definitely a much more substantial project than the little toy I created.)
Today, I have a new version that can effectively be run from the command line. (I believe that the approach I use could also work for the MacroPy project). This is version 4 found in this github repository.
I will start with a concrete example taken from the repository (file test.py); the code below contains keywords and constructs that are definitely not valid in Python.
If you try to run this program from the command line using "python test.py" at your command/shell prompt ... it will definitely fail. However, using the code from the repository, you can run it via "python import_experimental.py test". The code inside import_experimental.py, which has many more comments than I would normally write, is the following:
One could easily write a shell script/bat file which would simplify execution to something like "my_python test"
It would be nice to remove the "imp" dependency and use the proper functions/methods from the importlib module, something which I have not been able to figure out (yet). Anyone familiar with the importlib module is more than welcome to do it and tell me about it. ;-)
Also, writing more useful code converters than the two toy ones I created would likely be an interesting project.
In a post I wrote yesterday, I mentioned a way to run "experimental" code containing non-standard Python syntax (e.g. new keywords, not recognized by Python's interpreter) by using an "import hook" to convert the code into a proper Python syntax prior to executing it. One caveat of the approach I used was that it only worked if the "experimental" code was imported. This restriction is also present in the MacroPy project (which is something I stumbled upon and is definitely a much more substantial project than the little toy I created.)
Today, I have a new version that can effectively be run from the command line. (I believe that the approach I use could also work for the MacroPy project). This is version 4 found in this github repository.
I will start with a concrete example taken from the repository (file test.py); the code below contains keywords and constructs that are definitely not valid in Python.
'''This is not a valid Python module as it contains two
non-standard keywords: repeat and function. However,
by using a custom importer, and the presence of the special
import line below, these non-standard keywords will be converted
into valid Python syntax prior to execution.
'''
from __experimental__ import repeat_keyword, function_keyword # magic! :-)
def normal_syntax():
'''Creates the list [4, 4, 4] by using the normal Python syntax,
with a for loop and a lambda-defined function.
'''
res = []
g = lambda x: x**2
for _ in range(3):
res.append(g(2))
return res
def experimental_syntax():
'''Creates the list [4, 4, 4] by using an experimental syntax
with the keywords "repeat" and "function", otherwise
using the same algorithm as the function called "normal_syntax".
'''
res = []
g = function x: x**2
repeat 3:
res.append(g(2))
return res
if __name__ == '__main__':
if normal_syntax() == experimental_syntax():
print("Success")
else:
print("Failure")
If you try to run this program from the command line using "python test.py" at your command/shell prompt ... it will definitely fail. However, using the code from the repository, you can run it via "python import_experimental.py test". The code inside import_experimental.py, which has many more comments than I would normally write, is the following:
''' A custom Importer making use of the import hook capability
https://www.python.org/dev/peps/pep-0302/
Its purpose is to convert would-be Python module that use non-standard
syntax into a correct form prior to importing them.
'''
# imp is deprecated but I wasn't (yet) able to figure out how to use
# its replacement, importlib, to accomplish all that is needed here.
import imp
import re
import sys
MAIN = False
from_experimental = re.compile("(^from\s+__experimental__\s+import\s+)")
class ExperimentalImporter(object):
'''According to PEP 302, an importer only requires two methods:
find_module and load_module.
'''
def find_module(self, name, path=None):
'''We don't need anything special here, so we just use the standard
module finder which, if successful,
returns a 3-element tuple (file, pathname, description).
See https://docs.python.org/3/library/imp.html for details
'''
self.module_info = imp.find_module(name)
return self
def load_module(self, name):
'''Load a module, given information returned by find_module().
'''
# According to PEP 302, the following is required
# if reload() is to work properly
if name in sys.modules:
return sys.modules[name]
path = self.module_info[1] # see find_module docstring above
module = None
if path is not None: # path=None is the case for some stdlib modules
with open(path) as source_file:
module = self.convert_experimental(name, source_file.read())
if module is None:
module = imp.load_module(name, *self.module_info)
return module
def convert_experimental(self, name, source):
'''Used to convert the source code, and create a new module
if one of the lines is of the form
^from __experimental__ import converter1 [, converter2, ...]
(where ^ indicates the beginning of a line)
otherwise returns None and lets the normal import take place.
Note that this special code must be all on one physical line --
no continuation allowed by using parentheses or the
special \ end of line character.
"converters" are modules which must contain a function
transform_source_code(source)
which returns a tranformed source.
'''
global MAIN
lines = source.split('\n')
for linenumber, line in enumerate(lines):
if from_experimental.match(line):
break
else:
return None # normal importer will handle this
# we started with: "from __experimental__ import converter1 [,...]"
line = from_experimental.sub(' ', line)
# we now have: "converter1 [,...]"
line = line.split("#")[0] # remove any end of line comments
converters = line.replace(' ', '').split(',')
# and now: ["converter1", ...]
# drop the "fake" import from the source code
del lines[linenumber]
source = '\n'.join(lines)
for converter in converters:
mod_name = __import__(converter)
source = mod_name.transform_source_code(source)
module = imp.new_module(name)
# From PEP 302: Note that the module object must be in sys.modules
# before the loader executes the module code.
# This is crucial because the module code may
# (directly or indirectly) import itself;
# adding it to sys.modules beforehand prevents unbounded
# recursion in the worst case and multiple loading in the best.
sys.modules[name] = module
if MAIN: # see below
module.__name__ = "__main__"
MAIN = False
exec(source, module.__dict__)
return module
sys.meta_path = [ExperimentalImporter()]
if __name__ == '__main__':
if len(sys.argv) >= 1:
# this program was started by
# $ python import_experimental.py some_script
# and we will want some_script.__name__ == "__main__"
MAIN = True
__import__(sys.argv[1])
One could easily write a shell script/bat file which would simplify execution to something like "my_python test"
It would be nice to remove the "imp" dependency and use the proper functions/methods from the importlib module, something which I have not been able to figure out (yet). Anyone familiar with the importlib module is more than welcome to do it and tell me about it. ;-)
Also, writing more useful code converters than the two toy ones I created would likely be an interesting project.
from __experimental__ import something_new
Python programmers are used to the notation:
which allows to experiment with changes that are to become part of a future Python version. These are hard-coded in the Python interpreter and cannot be created at will by an average Python programmer. Wouldn't it be nice if there was a simple way to try out possible new syntax by an average Python programmer? This blog post describes a way to do this, with a link to working code. The code is not very sophisticated: firstly, I am not a professional programmer and have no training in computer science; as a result, all I do is simple stuff. Secondly, I wrote the bulk of the code in a single day (ending with this blog post); I am sure it could be greatly improved upon.
However, like I say to beginners on various forums: the important thing is to first make your program do what you want it to.
Before I discuss the details of the code, I am going to make a rather long digression to explain my original motivation and what I found along the way.
Anyone that has read more than a few posts on this blog is likely familiar with my Python implementations of Karel the Robot: a desktop version, named RUR-PLE, and a more modern and sophisticated web version, Reeborg's World. In what follows, I will give examples using code that could be readily executed in Reeborg's World. These are extremely simple ... but I give them to illustrate a very important point about what motivated me.
Reeborg is a faulty robot. It can move forward and turn left (by 90 degrees) as follows:
However, it cannot turn right directly. Nonetheless, one can define a new function to make it turn right by doing three consecutive left turns:
Reeborg (like the original Karel) can make single decisions based on what it senses about its environment
What if we wanted Reeborg to draw a square? If I were to use Guido van Robot, Python-like implementation, I would write the following
Once again, no variable nor any function arguments. However, if I wanted to do the same thing in Reeborg's World, at least up until a few days ago days ago, I would have needed to write:
So much for the idea of not having variables nor function arguments .... I've always hated the "don't worry about it now" kind of statements made to students. However, the alternative is to explain a rather complicated expression (for beginners at this stage, especially young children who have never seen algebra and the idea of a variable) ... Wouldn't it be nice if
one could write instead:
or, if one does not want to introduce a new keyword, write
and have Python recognize it as having the same meaning?... So, I subscribed to the python-ideas list and made this suggestion. The result was more or less what I was expected... And, to be honest, I completely understand the reluctance to introduce such a change. While I expected a lack of support for this suggestion, (and, to be honest, I wasn't myself convinced that it fitted entirely Python's design philosophy) I wasn't expecting the amount of heat it would generate ... However, a couple of people with experience teaching to young children were sympathetic, including Luciano Ramalho. Terry Jan Reedy, who thought I was using IDLE, suggested that I just patch it and transform the code prior to execution. Since I was already transforming the code prior to execution to support line highlighting in Reeborg's World, it was rather trivial to add yet one more code transformation to support the "repeat" keyword as illustrated above.
So, I have a way to support a "repeat" keyword in Reeborg's World ... but it left me somewhat unsatisfied to have something like this not easily available elsewhere in the Python world.
In one of his posts to python-ideas, Terry Jan Reddy mentioned a discussion on the idle-dev list about making idle friendlier to beginners. In one of his post, he mentioned the idea of having non-English keywords. This idea is not new. There already exists an unmaintained version with Chinese Keywords as well as a Lithuanian and Russion version. Maintaining a version based on a different language for keywords is surely not something simple ... nor I think it would be desirable. However, it might be possible to essentially achieve the same goal by using an approach I describe in the next section.
Even just adding new keywords can be quite difficult. For example, in this post, Eli Bendersky explains how one can add a new keyword to Python. "All" you ned to do is
it will support constructs like
If instead, it has
then one will be able to write "function" instead of "lambda" (which has been identified as one of Python's warts by a few people including Raymond Hettinger.)
One can combine two transformations as follows:
and both functions will have exactly the same meaning. One caveat: this works only when a module is imported.
Each code transformer, such as repeat_keyword.py and function_keyword.py, contains a function named "transform_source_code"; this function takes an existing source code as input and returns a modified version of that code. These transformations can thus be chained easily, where the
output from one transformation is taken as the input from another.
The transformation happens when a module is imported using an import statement; this is an unfortunate limitation as one can not execute
The magic occurs via an import hook. The code I have written uses the deprecated imp module. I have tried to figure out how to use the importlib module to accomplish the same thing ... but I failed. I would be greatful to anyone who could provide help with this.
When PEPs are written, they often contain small sample codes. When I read PEPs which are under discussion, I often wish I could try out to write and modify such code samples to see how they work. While not all proposed code could be made to work using the approach I have described, it might be possible in many cases. As an example, PEP 0465 -- A dedicated infix operator for matrix multiplication could almost certainly have been implemented as a proof-of-concept using the approach I used. I suspect that the existence of the appropriate code converter would often enrich the discussions about proposed changes to Python, and allow for a better evaluation of different alternatives.
Python support the special "from __future__ import ..." construct to determine how it will interpret the rest of the code in that file. I think it would be useful if a similar kind of statement "from __experimental import ..." would also benefit from the same kind of special treatment so that it
would work in all instances, and not only when a module is imported. People could then share (and install via pip) special code importers and know that they would work in all situations, and not limited to special environments like Reeborg's World, or IDLE as suggested by T.J. Reddy and likely others.
However, a concrete suggestions along these lines will have to wait for another day...
from __future__ import new_functionality
which allows to experiment with changes that are to become part of a future Python version. These are hard-coded in the Python interpreter and cannot be created at will by an average Python programmer. Wouldn't it be nice if there was a simple way to try out possible new syntax by an average Python programmer? This blog post describes a way to do this, with a link to working code. The code is not very sophisticated: firstly, I am not a professional programmer and have no training in computer science; as a result, all I do is simple stuff. Secondly, I wrote the bulk of the code in a single day (ending with this blog post); I am sure it could be greatly improved upon.
However, like I say to beginners on various forums: the important thing is to first make your program do what you want it to.
Before I discuss the details of the code, I am going to make a rather long digression to explain my original motivation and what I found along the way.
Something special about Pattis's Karel the Robot
Anyone that has read more than a few posts on this blog is likely familiar with my Python implementations of Karel the Robot: a desktop version, named RUR-PLE, and a more modern and sophisticated web version, Reeborg's World. In what follows, I will give examples using code that could be readily executed in Reeborg's World. These are extremely simple ... but I give them to illustrate a very important point about what motivated me.
Reeborg is a faulty robot. It can move forward and turn left (by 90 degrees) as follows:
move() turn_left()
However, it cannot turn right directly. Nonetheless, one can define a new function to make it turn right by doing three consecutive left turns:
def turn_right():
turn_left()
turn_left()
turn_left()
Reeborg (like the original Karel) can make single decisions based on what it senses about its environment
if wall_in_front():
turn_left()
else:
move()
or it can make repeated decisions in a similar way:while not wall_in_front():
move()
Using simple commands and conditions, beginners can learn the basics of programming using such an environment. Notice something important in the above code samples: no variables are used and there are no function arguments.What if we wanted Reeborg to draw a square? If I were to use Guido van Robot, Python-like implementation, I would write the following
do 4:
move
turnleft
Once again, no variable nor any function arguments. However, if I wanted to do the same thing in Reeborg's World, at least up until a few days ago days ago, I would have needed to write:
for var in range(4):
move()
turn_left()
So much for the idea of not having variables nor function arguments .... I've always hated the "don't worry about it now" kind of statements made to students. However, the alternative is to explain a rather complicated expression (for beginners at this stage, especially young children who have never seen algebra and the idea of a variable) ... Wouldn't it be nice if
one could write instead:
repeat 4:
move()
turn_left()
for 4:
move()
turn_left()
So, I have a way to support a "repeat" keyword in Reeborg's World ... but it left me somewhat unsatisfied to have something like this not easily available elsewhere in the Python world.
Additional motivation
In one of his posts to python-ideas, Terry Jan Reddy mentioned a discussion on the idle-dev list about making idle friendlier to beginners. In one of his post, he mentioned the idea of having non-English keywords. This idea is not new. There already exists an unmaintained version with Chinese Keywords as well as a Lithuanian and Russion version. Maintaining a version based on a different language for keywords is surely not something simple ... nor I think it would be desirable. However, it might be possible to essentially achieve the same goal by using an approach I describe in the next section.
Even just adding new keywords can be quite difficult. For example, in this post, Eli Bendersky explains how one can add a new keyword to Python. "All" you ned to do is
- Modify the grammar to add the new keyword
- Modify the AST generation code; this requires a knowledge of C
- Compile the AST into bytecode
- Recompile the modified Python interpreter
Not exactly for the faint of heart...
A simpler way...
Using the unmodified standard Python interpreter, I have written some proof-of-concept code which works when importing modules that satisfy certain conditions. For example, if an imported module
contains as its first line
for __experimental__ import repeat_keyword
it will support constructs like
repeat 4:
move()
turn_left()
If instead, it has
from __experimental__ import function_keyword
then one will be able to write "function" instead of "lambda" (which has been identified as one of Python's warts by a few people including Raymond Hettinger.)
One can combine two transformations as follows:
from __experimental__ import repeat_keyword, function_keyword
def experimental_syntax():
res = []
g = function x: x**2
repeat 3:
res.append(g(2))
return res
def normal_syntax():
res = []
g = lambda x: x**2
for i in range(3):
res.append(g(2))
return res
and both functions will have exactly the same meaning. One caveat: this works only when a module is imported.
How does it work?
Each code transformer, such as repeat_keyword.py and function_keyword.py, contains a function named "transform_source_code"; this function takes an existing source code as input and returns a modified version of that code. These transformations can thus be chained easily, where the
output from one transformation is taken as the input from another.
The transformation happens when a module is imported using an import statement; this is an unfortunate limitation as one can not execute
python non_standard_module.pyfrom the command line and expect "non_standard_module.py" to be converted.
The magic occurs via an import hook. The code I have written uses the deprecated imp module. I have tried to figure out how to use the importlib module to accomplish the same thing ... but I failed. I would be greatful to anyone who could provide help with this.
Other potential uses
In addition to changing the syntax slightly to make it easier to (young) beginners, or to make it easier to understand to non-English speaker especially if they use a different character set, more experienced programmers might find this type of code transformation potentially useful.When PEPs are written, they often contain small sample codes. When I read PEPs which are under discussion, I often wish I could try out to write and modify such code samples to see how they work. While not all proposed code could be made to work using the approach I have described, it might be possible in many cases. As an example, PEP 0465 -- A dedicated infix operator for matrix multiplication could almost certainly have been implemented as a proof-of-concept using the approach I used. I suspect that the existence of the appropriate code converter would often enrich the discussions about proposed changes to Python, and allow for a better evaluation of different alternatives.
A suggestion to come?...
I'm not ready yet to bring another suggestion to the python-ideas list ... However ...Python support the special "from __future__ import ..." construct to determine how it will interpret the rest of the code in that file. I think it would be useful if a similar kind of statement "from __experimental import ..." would also benefit from the same kind of special treatment so that it
would work in all instances, and not only when a module is imported. People could then share (and install via pip) special code importers and know that they would work in all situations, and not limited to special environments like Reeborg's World, or IDLE as suggested by T.J. Reddy and likely others.
However, a concrete suggestions along these lines will have to wait for another day...
Friday, June 19, 2015
Generating mazes
While Reeborg's World was primarily designed for beginners, it can be used to illustrate relatively advanced topics in a fun way. For example, one can generate mazes using a depth-first algorithm.

Of course, generating mazes is only half the fun: the real fun is to use them to set Reeborg on a treasure hunt:
 Fairly large mazes can be generated, but it does take a fair bit of time. I'm using many generic functions written for the world editor to change the world configuration; these are well-tested and designed for fool-proof interactive use, adding or removing one element at a time. A more efficient way would be to manipulate directly the world object (implemented as a mixture of dict and lists - to use the Python terms, although they are in this case the javascript equivalents).
Fairly large mazes can be generated, but it does take a fair bit of time. I'm using many generic functions written for the world editor to change the world configuration; these are well-tested and designed for fool-proof interactive use, adding or removing one element at a time. A more efficient way would be to manipulate directly the world object (implemented as a mixture of dict and lists - to use the Python terms, although they are in this case the javascript equivalents).
 For those interested, the details can be found here.
For those interested, the details can be found here.

Of course, generating mazes is only half the fun: the real fun is to use them to set Reeborg on a treasure hunt:


Tuesday, June 16, 2015
Reeborg meets Sokoban
I have been very busy these past few weeks in revamping Reeborg's World. Since some incompatible changes with the previous version have been made and since some teachers are currently using the old version, the link points to a new (and temporary) location for the development version.
Instead of supporting only "boring looking" traditional "Karel-the-robot" worlds,
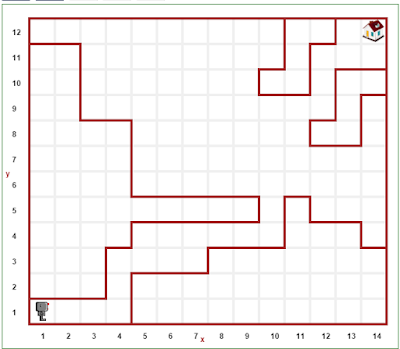
One can create logically-equivalent, but much more interessting looking puzzles:

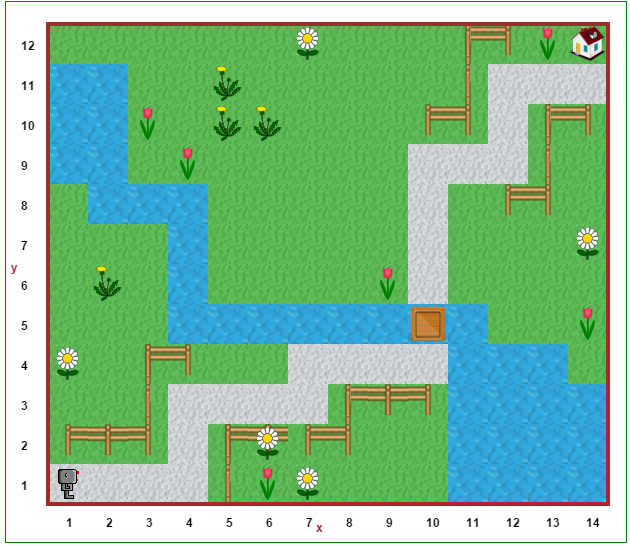
It even support supports the creation of Sokoban-type puzzles:

Pushable boxes, can become bridges enabling crossing water obstacles

If you want to find out more, you should have a look at the new documentation, in particular the advanced features section. I still have a bit of work to do on the documentation, but it is already fairly comprehensive.
Check it out and feel free to share any world/puzzle/task you create! :-)
Instead of supporting only "boring looking" traditional "Karel-the-robot" worlds,

One can create logically-equivalent, but much more interessting looking puzzles:
It even support supports the creation of Sokoban-type puzzles:

Pushable boxes, can become bridges enabling crossing water obstacles

If you want to find out more, you should have a look at the new documentation, in particular the advanced features section. I still have a bit of work to do on the documentation, but it is already fairly comprehensive.
Check it out and feel free to share any world/puzzle/task you create! :-)
Friday, April 17, 2015
Loopy else in Python
I love Python. Yet, there are some minor things in the language that I find baffling...
Python loop statements (for/while) include an optional else clause whose behaviour is very counter intuitive. In fact, it is so "bad" that Brett Slatkin, author of Effective Python, wrote as one of his 59 specific ways to write better Python:
In fact, Guido himself wrote in 2009:
(My initial preference, when I learned about the meaning of else in those loops, was to wonder why "ifnobreak" had not bee used as a keyword instead; later I saw Raymond Hettinger suggest simply "nobreak" which I thought was both more readable and a better idea. [You can see Hettinger explain why in this video.] However, Guido also mentioned in the above quoted message "I would *not* choose another keyword.")
In the official Python tutorial, when the else clause is discussed, we find these two interesting statements:
And it seems it's going to get only worse. In a new PEP, we see that another similar else clause is proposed with the similar semantic...
Python loop statements (for/while) include an optional else clause whose behaviour is very counter intuitive. In fact, it is so "bad" that Brett Slatkin, author of Effective Python, wrote as one of his 59 specific ways to write better Python:
Item 12: Avoid else Blocks After for and while Loops.
In fact, Guido himself wrote in 2009:
I would not have the feature at all if I had to do it over.
(My initial preference, when I learned about the meaning of else in those loops, was to wonder why "ifnobreak" had not bee used as a keyword instead; later I saw Raymond Hettinger suggest simply "nobreak" which I thought was both more readable and a better idea. [You can see Hettinger explain why in this video.] However, Guido also mentioned in the above quoted message "I would *not* choose another keyword.")
In the official Python tutorial, when the else clause is discussed, we find these two interesting statements:
Yes, this is the correct code. Look closely: the else clause belongs to the for loop, not the if statement.(I don't know about you, but when I read some similar warning in a tutorial, my immediate reaction is to question why it was done like this in the first place since it is recognized as being far from obvious.)
When used with a loop, the else clause has more in common with the else clause of a try statement than it does that of if statements...This is yet another acknowledgement that people might be confused about the meaning of "else", since they mostly see it with "if" statements.
And it seems it's going to get only worse. In a new PEP, we see that another similar else clause is proposed with the similar semantic...
async for TARGET in ITER:
BLOCK
else:
BLOCK2Why, oh why can we not introduce a clearer keyword (like nobreak) and stop introducing yet more examples of confusingly named clause...
Thursday, January 29, 2015
Type hinting in Python: focus on readability
tl;dr: the proposed type hinting for Python is done to help tools analyze code better (which can be very useful for programmers) but at the cost of reduced readability. A different idea is discussed which focuses on readability.
----
So, Python is going to have some type hinting [PEP484].
I agree with the idea that lead to this addition to Python; however, I find that the syntax proposed is less than optimal. Thinking about how it came about, it is not entirely surprising.
- Functions annotations were introduced in 2006 [PEP3107].
- Various libraries worked within the constraints and limitations imposed by this new addition, including mypy [mypy].
- PEP 484 is "strongly inspired by mypy" essentially using it as a starting point. However, it indirectly acknowledges that the syntax chosen is less than optimal:
If type hinting proves useful in general, a syntax for typing variables may be provided in a future Python version. [PEP484]
What if [PEP3107] had never been introduced nor accepted and implemented, and we wanted to consider type hinting in Python?...
Why exactly is type hinting introduced?
As stated in [PEP484]:
"This PEP aims to provide a standard syntax for type annotations, opening up Python code to easier static analysis and refactoring, potential runtime type checking, and performance optimizations utilizing type information."
The way I read this is as follows: type hinting is primarily introduced to help computerized tools analyze Python code.
I would argue that, a counterpart to this would be that type hinting should not be a hindrance to humans; in particular, it should have a minimal impact on readability. I would also argue that type hinting, as it is proposed and discussed, does reduce readability significantly. Now, let's first have a look at some specific examples given, so that you can make your own opinion as to how it would affect readability.
Simple example (from [PEP484]):
I will start with a very simple examples for those who might not have seen
the syntax discussed.
def greeting(name: str) -> str:
return 'Hello ' + name
Within the function arguments, the type annotation is denoted by
a colon (:); the type of the return value of the function is done
by a special combination of characters (->) that precede the colon which
indicates the beginning of a code block.
Slightly more complicated example (from [mypy])
def twice(i: int, next: Function[[int], int]) -> int:
return next(next(i))
We now have two arguments; it becomes a bit more difficult to see at a
glance what the arguments for the function are. We can improve upon this
by formatting the code as follows:
def twice(i: int,
next: Function[[int], int]) -> int:
return next(next(i))
What about keyword-based arguments?
From [PEP483]
"There is no way to indicate optional or keyword arguments, nor varargs (we don't need to spell those often enough to complicate the syntax)"
From [PEP484]
"Since using callbacks with keyword arguments is not perceived as a common use case, there is currently no support for specifying keyword arguments with Callable."
However, some discussions are taking place; here is an example taken from https://github.com/ambv/typehinting/issues/18 (formatted in a more readable way than found on that site)
def retry(callback: Callable[AnyArgs, Any[int, None]],
timeout: Any[int, None]=None,
retries=Any[int, None]=None) -> None:
Can you easily read off the arguments of this function? Did I forget one argument when I split the argument lists over three lines? Can you quickly confirm that the formatting is not misleading?
Type Hints on Local and Global Variables
The following is verbatim from [PEP484]
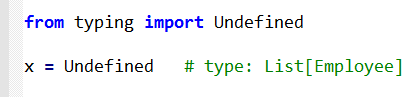
No first-class syntax support for explicitly marking variables as being of a specific type is added by this PEP. To help with type inference in complex cases, a comment of the following format may be used:
x = [] # type: List[Employee]
In the case where type information for a local variable is needed before if was declared, an Undefined placeholder might be used:
from typing import Undefined
x = Undefined # type: List[Employee]
y = Undefined(int)
If type hinting proves useful in general, a syntax for typing variables may be provided in a future Python version.(emphasis added)
Edit: why not bite the bullet and do it now? Considering what this syntax, if it were introduced, should look like, might reassure people who see type information in comments as problematic and ensure that the limited syntax decided upon in this PEP will not have to be changed to be made coherent with the new addition(s).
What about class variables?
I have yet to see them being discussed. I assume that they would be treated the same as local and global variables, with an as yet undefined syntax.
A different proposal for type hinting.
Let's forget for a moment the syntax introduced by [PEP3107] for functions annotations, and imagine that we are considering everything from the beginning.
Type hinting is introduced for tools (linters, etc.). As such, I would assume the following:
When reading/parsing code:
- type hinting information should be easily identifiable by tools
- type hinting information should be easily ignorable by humans (if they so desire)
By this, I mean that the type hinting information should not decrease significantly the readability of the code.
Let me start with an obvious observation about Python: indentation based code-blocks indicate the structure. Code blocks are identified by their indentation level, which is the same within a code block.
Tools, like the Python interpreter, are very good at identifying code blocks. Adding an new type of code block to take into account by these tools should be straightforward.
A secondary observation is that comments, which are ignored by Python, are allowed to deviate from the vertical alignment within a given code block as illustrated below.
def f():
x = 1
y = 2
# this comment is not aligned
# with the rest of the code.
if z:
pass
Now, suppose that we could use a syntax where type annotation was structured around code-blocks defined by their indentation. Since type annotation are meant to be ignored by the interpreter (non executable, like comments), let us also give the freedom to have additional indentation for those ignorable code-blocks, like we do for comments.
The specific proposal
Add where as a new Python keyword; the purpose of this keyword is to introduce a code block in which type hinting information is given.
To see how this would work in practice, I will show screenshots of code from a syntax-aware editor containing type hinting information as it is proposed and contrasted with how it might look when using the "where code blocks". I'm using screenshots as it provides a truer picture of what code would really look like in real life situations.
First, the example from [mypy] shown above:

Now, the same example using the "where" code-block.


I used "return" instead of "->" as I find it more readable; however, "->" could be used just as well.
Having a code-block, I can use the code-folding feature of my editor to reduced greatly the visibility of the type hinting information; such code-folding could presumably be done automatically for all type-hinting code blocks.
Moving on to a more complicated example, also given above. First, the screenshot with the currently proposed syntax.

Next, using the proposed code-block; notice how keyword-based arguments are treated just the same as any other arguments. [Note: I was not sure if timeout above was a keyword based argument assigned a default value or not, since it used a different syntax from retries which is a keyword based argument.]

Again, using code-folding, the visual noise added by the type-hinting information essentially disappears.

Finally, the example with the "global variable", first with the proposed type hinting information added in a comment:
Next, using a code block; no need to import a special "type" to assign a special "Undefined" value: the standard None does the job.

A similar notation could easily be used for class variables, something which is not addressed by the current type-hinting PEP.
Type hinting information is going to be a useful feature for future Python programmers. I believe that using indentation based code blocks to indicate type hinting information would be much more readable that what has been discussed so far. Unfortunately, I also believe that it has no chance of being accepted, let alone considered seriously.
[PEP483] https://www.python.org/dev/peps/pep-0483/
[PEP484] https://www.python.org/dev/peps/pep-0484/
[PEP3107] https://www.python.org/dev/peps/pep-3107/
[mypy] http://mypy-lang.org/
This blog post is licensed under CC0 and was written purely with the intention to entertain.
Subscribe to:
Posts (Atom)