In the past week, there has been an interesting discussion on Python-ideas about Natural support for units in Python. As I have taught introductory courses in Physics for about 20 of the 30 years of my academic career, I am used to stressing the importance of using units correctly, but had never had the need to explore what kind of support for units was available in Python. I must admit to have been pleasantly surprised by many existing libraries.
In this blog post, I will give a very brief overview of parts of the discussion that took, and is still taking place, on Python-ideas about this topic. I will then give a very brief introduction to two existing libraries that provide support for units, before showing some actual code inspired by the Python-ideas discussion.
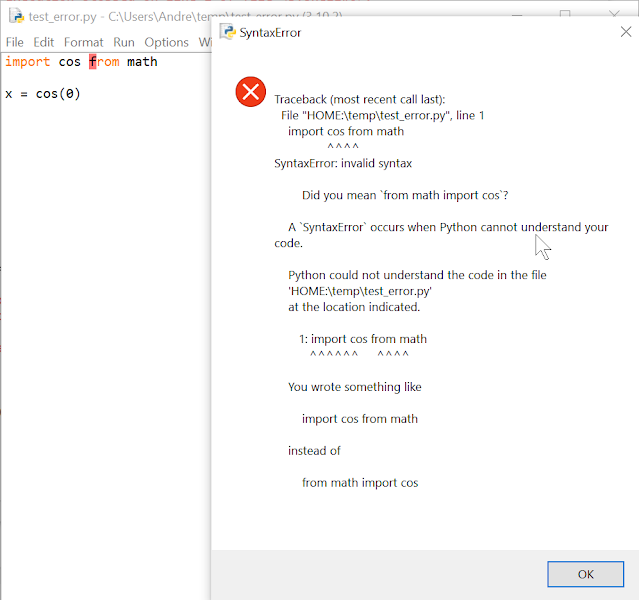
But first, putting my Physics teacher hat on, let me show you some partial Python code that I find extremely satisfying, and which contains a line that is almost guaranteed to horrify programmers everywhere, as it seemingly reuse the variable "m" with a completely different meaning.
>>> g = 9.8[m/s^2]
>>> m = 80[kg]
>>> weight = m * g
>>> weight
<Quantity(784.0, 'kilogram * meter / second ** 2')>
>>> tolerance = 1.e-12[N]
>>> abs(weight - 784[N]) < tolerance
True
Discussion on Python-ideas
The discussion on Python-ideas essentially started with the suggestion that "it would be nice if Python's syntax supported units". That is, if you could basically do something like:
length = 1m + 3cm
# or even
length = 1m 3cm
and it just worked as "expected". Currently, identifiers in Python cannot start with a number, and writing "3cm" is a SyntaxError. So, in theory, one could add support for this type of construct without causing any backward incompatibility.
While I never thought of it before, as I use Python as a hobby, I consider the idea of supporting handling units correctly to be an absolute requirement for any scientific calculations. Much emphasis is being made on adding type information to ensure correctness: to my mind, adding *unit* information to ensure correctness is even more important than adding type information.
During the course of the discussion on Python-ideas, other possible suggestions were made, some of which are actually supported by at least a couple of existing Python libraries. These suggestions included constructs like the following:
length = 1*m + 3*cm
speed = 4*m / 1*s # or speed = 4 * m / s
length = m(1) + cm(3)
speed = m_s(4)
length = 1_m + 3_cm
speed = 4_m_s
length = 1[m] + 3[cm]
speed = 4[m/s]
length = 1"m" + 3"m"
speed = 4"m/s"
density = 1.0[kg/m**3]
density = 1.0[kg/m3]
# No one suggested something like the following
density = 1.0[kg/m^3]
I will come back to looking at potential new syntax for units, as it currently my main interest in this topic. But first, I want to highlight one other main point of the discussion on Python-ideas, namely: Should the units be defined globally for an entire application, or locally according to the standard Python scopes?
My first thought was "of course, it should follow Python's normal scopes".
Thinking of the opposite argument, what happen if one uses units other than S.I. units in different module, including those from external libraries? Take for example "mile", and have a look at its Wikipedia entry. If one uses units with the same name but different values in different parts of an application, any pretense of using quantities with units to ensure accuracy goes out the window. Furthermore, many units libraries make it possible for users to define they own custom units. What happens if the same name is used for different custom units in different modules, with variables or functions using variables with units in one module are used in a second module?
Still, as long as libraries do not, or cannot change unit definitions globally, and if they provide clear and well-documented access to the units they use, then the normal Python scopes would likely be the best choice.
[For a detailed discussion of these two points of view, have a look at the thread on Python-ideas mentioned above. There doesn't seem to be a consensus as to what the correct approach should be.]
A brief look at two unit libraries
There are many unit libraries available on Pypi. After a brief look at many of them, I decided to focus on only two: astropy.units and pint. These seemed to be the most complete ones currently available, with source code and good supporting documentation available.
I will first look at an example that shows how equivalent description of units are easily handled in both of them. First, I use the units module from astropy:
>>> from astropy import units as u
>>> p1 = 1 * u.N / u.m**2
>>> p1
<Quantity 1. N / m2>
>>> p2 = 1 * u.Pa
>>> p1 == p2
True
Next, doing the same with pint.
>>> import pint
>>> u = pint.UnitRegistry()
>>> p1 = 1 * u.N / u.m**2
>>> p1
<Quantity(1.0, 'newton / meter ** 2')>
>>> p2 = 1 * u.Pa
>>> p1 == p2
True
In astropy, all the units are defined in a single module. Instead of prefacing the units with the name of the module, one can import units directly
>>> from astropy.units import m, N, Pa
>>> p1 = 1 * N / m**2
>>> p2 = 1 * Pa
>>> p1 == p2
True
The same cannot be done with pint.
A custom syntax for units
As I was reading posts from the discussion on Python-ideas, I was thinking that it might be fun to come up with a way to "play" with some code written in a more user-friendly syntax for units. After reading the following, written by Matt del Valle, I decided that I should definitely do it.
My personal preference for adding units to python would be to make
instances of all numeric classes subscriptable, with the implementation
being roughly equivalent to:
def __getitem__(self, unit_cls: type[T]) -> T:
return unit_cls(self)
We could then discuss the possibility of adding some implementation of
units to the stdlib. For example:
from units.si import km, m, N, Pa
3[km] + 4[m] == 3004[m] # True
5[N]/1[m**2] == 5[Pa] # True
My first thought was to create a custom package building from and depending on astropy.units, as I had looked at it before looking at pint and found it to have everything one might need. However, as I read its rather unusual license, I decided that I should take another approach: I chose to simply add a new example to my ideas library, making it versatile enough so that it could be used with any unit library that uses the standard Python notation for multiplication, division and power of units, which both pint and astropy do. Note that my ideas library has been created to facilitate quick experiments and is not meant to be used in production code.
First, here's an example that mimics the example given by Matt del Valle above, with what I think is an even nicer (more compact) notation.
python -m ideas -t easy_units
Ideas Console version 0.0.29. [Python version: 3.9.10]
>>> from astropy.units import km, m, N, Pa
>>> 3[km] + 4[m] == 3004[m]
True
>>> 5[N/m^2] == 5[Pa]
True
In addition to allowing '**' for powers of units (not shown above), I chose to also recognize as equivalent the symbol '^' which is more often associated with exponentiation outside of the (Python) programming world.
Let's do essentially the same example using pint instead, and follow it with a few additional lines to illustrate further.
Ideas Console version 0.0.29. [Python version: 3.9.10]
>>> import pint
>>> unit = pint.UnitRegistry()
>>> 3[km] + 4[m] == 3004[m]
True
>>> 5[N/m^2] == 5[Pa]
True
>>> pressure = 5[N/m^2]
>>> pressure
<Quantity(5.0, 'newton / meter ** 2')>
>>> pressure = 5[N/m*m]
>>> pressure
<Quantity(5.0, 'newton / meter ** 2')>
In the last example, I made sure that "N/m*m" did not follow the regular left-to-right order of operation which might have resulted in unit cancellation as we first divide and then multiply by meters.
A look at some details
Using ideas with a "verbose" mode (-v or --verbose), one can see how the source is transformed prior to its execution. Furthermore, in the case of easy_units, sometime a "prefix" is "extracted" from the code, ensuring that the correct names are used. Here's a very quick look.
python -m ideas -t easy_units -v
Ideas Console version 0.0.29. [Python version: 3.9.10]
>>> import pint
>>> un = pint.UnitRegistry()
===========Prefix============
un.
-----------------------------
>>> pressure = 5[N/m^2]
===========Transformed============
pressure = 5 * un.N/(un.m**2)
-----------------------------
>>> pressure
<Quantity(5.0, 'newton / meter ** 2')>
Conclusion
Prior to reading the discussion on Python-ideas, I was only vaguely aware of the existence of some units libraries available in Python, and had no idea about their potential usefulness. Many unit libraries are, in my opinion, much less user-friendly than astropy and pint. Still, I do find the requirements to add explicit multiplication symbols to be more tedious and much less readable than the alternative that I have shown. While introducing a syntax like the one I have shown would not cause any backward incompatibilities, I doubt very much that anything like it would be added to Python, as it would likely be considered to be too specific to niche applications. I find this unfortunate ... However, I know that I can use ideas in my own projects if I ever want to use units together with a friendlier syntax.
I wrote the easy_units module in just a few hours. It is likely to contain some bugs [1], and is most definitely written as a quick hack not following the best practice. If you do try it, and find some bugs, feel free to file an issue; don't bother looking at the code. ;-)
[1] Indeed, I found and fixed a couple while writing this post.